Project: Google Maps Crawler 🗺🪲

Stack: Python, Selenium
 guilatrova
guilatrovaThis is the first project created for the Antifragile Dev series, and its purpose is to collect data from Google Maps and do pretty much whatever we want with it.
🤖 What is Selenium
Let's keep it simple: Selenium is a tool that manipulates and interacts with the browser as a regular user would.
It can be used to automate tests by simulating user behavior e.g. like typing, clicking, scrolling, interacting with contents, and checking outputs are being correctly displayed.
For the scope of this project, I didn't test anything, instead, I used it to capture data that would be very boring to do manually - we call it "web scrapping".
Create a Selenium Webdriver
This is how it looks like to create a "Selenium web driver" that will interact with Google Chrome:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
IMPLICT_WAIT = 5
def create_driver(headless=False):
chrome_options = Options()
if headless: # 👈 Optional condition to "hide" the browser window
chrome_options.headless = True
driver = webdriver.Chrome(ChromeDriverManager().install(), chrome_options=chrome_options)
# 👆 Creation of the "driver" that we're using to interact with the browser
driver.implicitly_wait(IMPLICT_WAIT)
# 👆 How much time should Selenium wait until an element is able to interact
return driver
👆 Note we're using ChromeDriverManager to install the required dependencies for Selenium to manipulate the Chrome browser. That makes the setup a lot easier!
The minimum knowledge you need to get started now:
- Visit a page
- Find an element on the page you want to interact
- Wait for something to happen
- Interact with the element
To be able to do any of those is important that you understand a thing or two about HTML, check some basic commands:
driver = create_driver() # Method defined in previous examples
driver.get(url) # 👈 Visits a page
# 👇 Finding elements
driver.find_elements(By.XPATH, "*") # 👈 Get all direct elements
driver.find_element(By.CSS_SELECTOR, "#btn") # 👈 Get one element with id "btn"
driver.find_elements(By.TAG_NAME, "h1") # 👈 Get all 'h1' elements
driver.find_elements(By.CLASS_NAME, "cls") # 👈 Get all elements with classname "cls"Defining "the best" way to find an element is harder though...
🐛 How to debug Selenium with VSCode
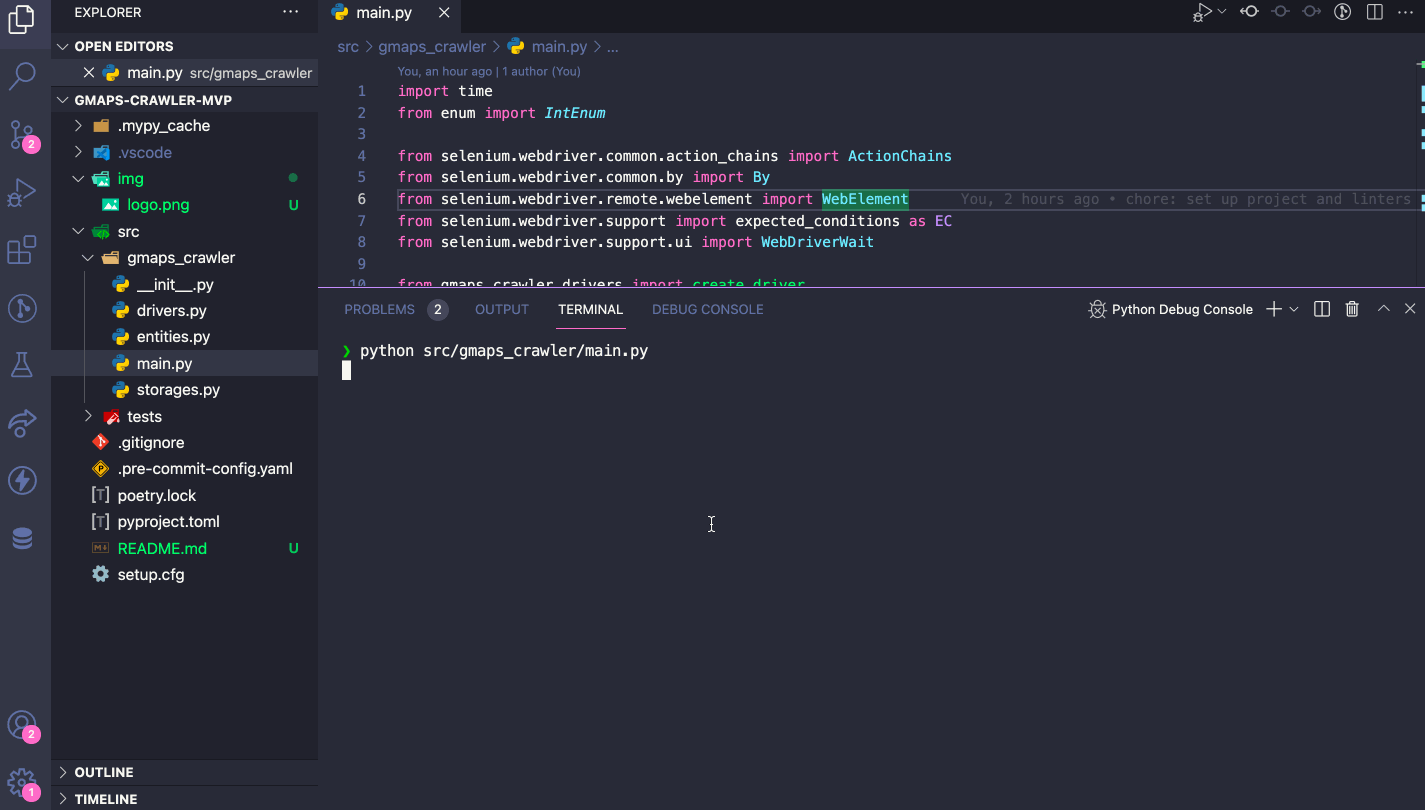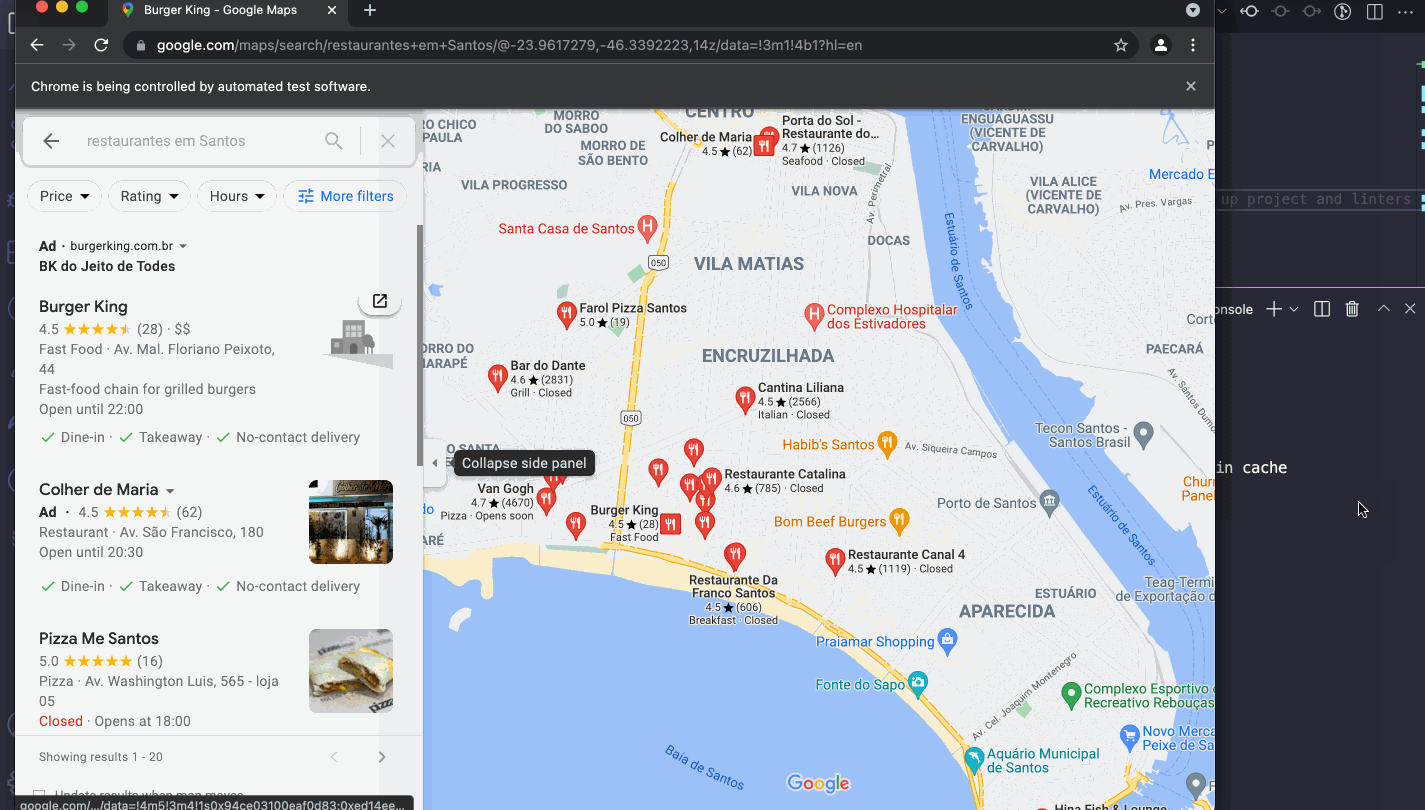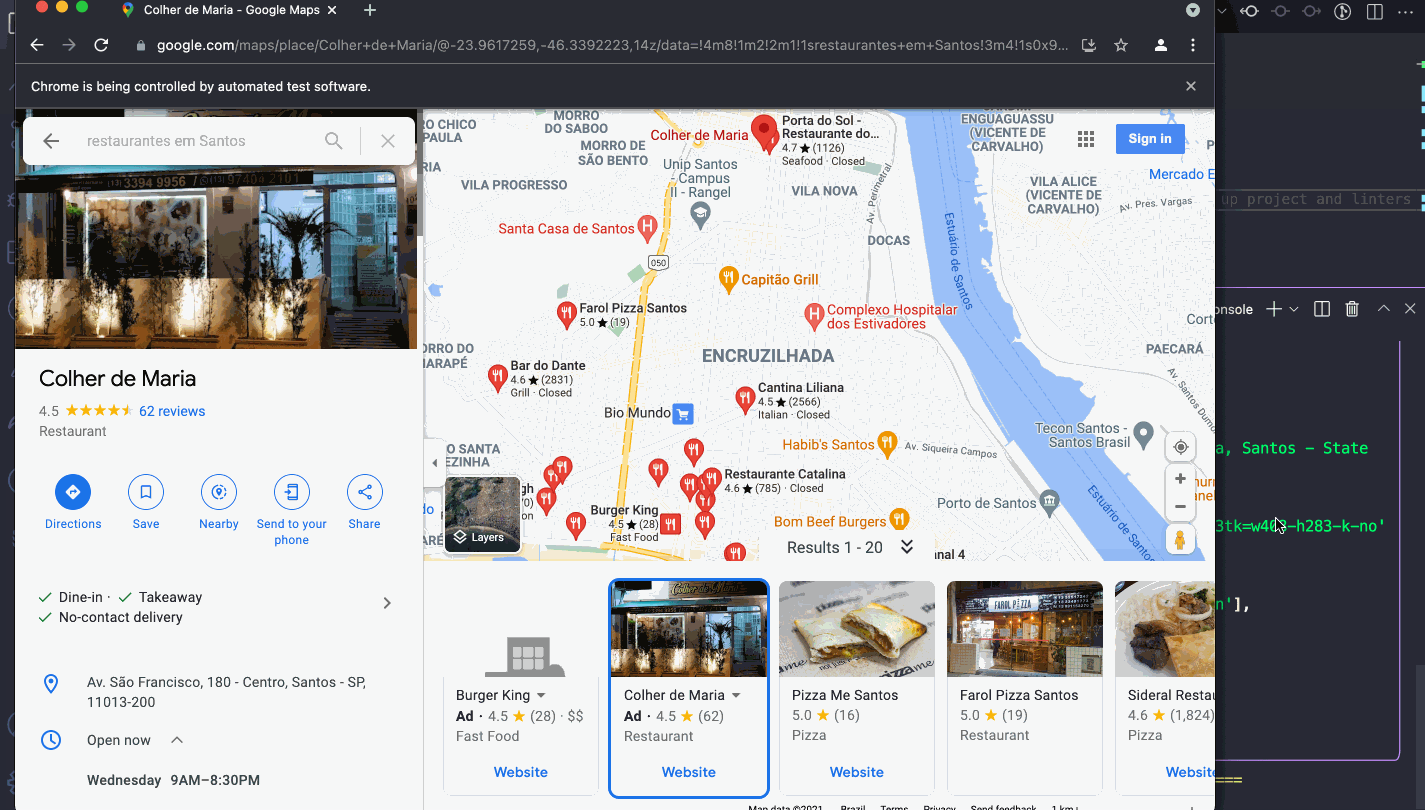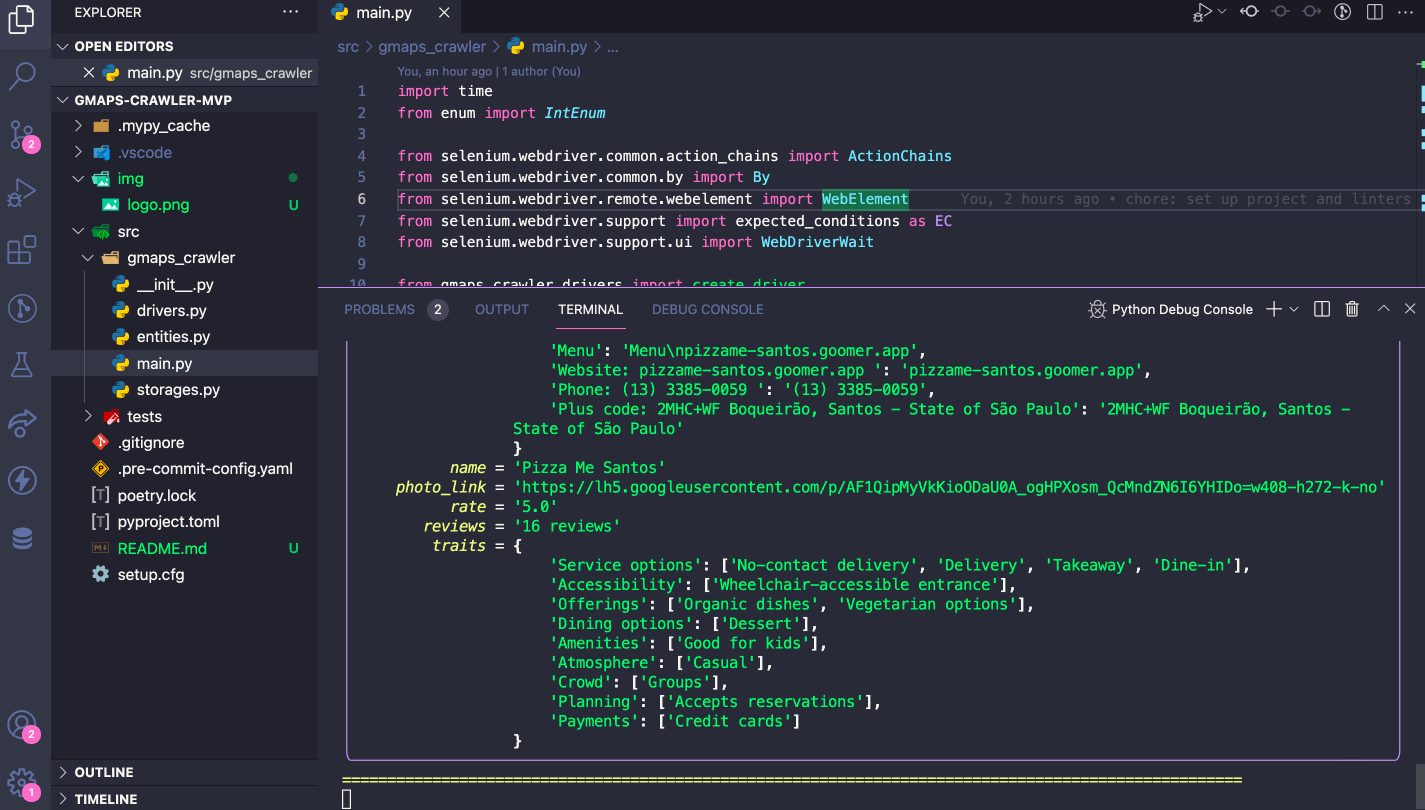
My debug process for such applications is always the same. These sites don't want to help you scrap their content, so they make it really hard with random ids and class names.
Consider you want to get the business hours from a restaurant, it's not as straightforward as it looks like, because nothing makes much sense:
To scrape data from such sites it's quite painful, and consider they might change it anytime and of course they won't notify you.
This is hard to do at a first shot, so I'm sharing some tricks I do to make my life less painful. You can set breakpoints in VSCode at specific moments, and then manipulate the driver right from the debug window.
It's great to minimize guesswork.
💡 Tips and challenges on scraping data with Python and Selenium!
— Gui Latrova (@guilatrova) November 17, 2021
1️⃣ Data inconsistency
As I was trying to scrape business hours from restaurants on Google Maps, I found some random text in the middle! [...]
👇🧵 Solution and more challenges in thread pic.twitter.com/gAEPbP7hOM
Finally, ensure to make your code readable, Selenium scripts get messy very quickly, so you always want meaningful methods and functions.
Check a small piece of this project code:
def get_place_details(self):
self.wait_restaurant_title_show()
# DATA
restaurant_name = self.get_restaurant_name()
address = self.get_address()
place = Place(restaurant_name, address)
if self.expand_hours():
place.business_hours = self.get_business_hours()
# TRAITS
place.extra_attrs = self.get_place_extra_attrs()
traits_handler = self.get_region(PlaceDetailRegion.TRAITS)
traits_handler.click()
place.traits = self.get_traits()
# REVIEWS
place.rate, place.reviews = self.get_review()
# PHOTOS
place.photo_link = self.get_image_link()
self.storage.save(place)
self.hit_back()The goal is for the code to be self-explanatory and simple to read.
🤔 Why you didn't use the Google Maps API?
Mostly due to some feature limitations and rate-limiting.
Also, I'm still hacking this project and I don't even know whether it will work, so I felt like just trying to get something simple real quick to move on.
🟢 What's next?
Since we're willing to build a microservice architecture, we took our initial step:
- To get some source of data to display
Now we must publish it to SQS as an event. Unfortunately, we don't have any infra yet... Well, I guess it's time for terraform and CDK. If you don't know those yet, it will be your chance to learn something fun and implemented in a real project.
Watch out for the next blog posts!
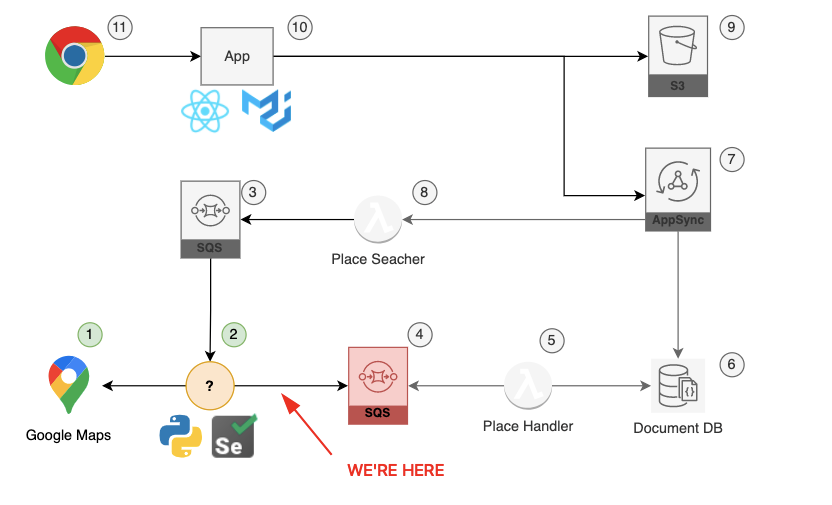
🟡 What's pending?
I made a few decisions that are worth sharing:
The application is not scaling yet
The application doesn't crawl until the last page
I'm running it from my own computer
👆 I don't want to bother about collecting more cities, running into other schedules, etc. I'll get back to it later. We must progress and deliver something simpler but working, and having ~10 restaurants is enough for now.
Follow me on Twitter to keep watching as the project evolves!
How to use Python 🐍 iterators IRL applied to a real project!
— Gui Latrova (@guilatrova) November 18, 2021
Let's go step-by-step on how to transform 💩 code in art:
👇🧵 Open Source Repository at the end pic.twitter.com/DQf4wK34nZ
