Logging in Python like a PRO 🐍🌴
Beyond exception handling, there's something else I see people struggling with, which is logging.
Most people don't know what to log, so they decide to log anything thinking it might be better than nothing, and end up creating just noise. Noise is a piece of information that doesn't help you or your team understand what's going on or resolving a problem.
Furthermore, I feel people are uncertain about how to use log levels, and so they default to logger.info everywhere (when not using print statements).
Lastly, people seem clueless on how to config logging in python, they have no idea what are handlers, filters, formatters, etc.
My goal here is to clarify what good logging is, and how you should implement it. I'll try to give meaningful examples, and provide you a flexible rule of thumb that should be used when logging for ANY application you're ever going to build.
📖 Intro
Examples make things easier to visualize, let's consider a system where:
- Users can connect multiple integrations from third parties to list resources (e.g. GitHub, Slack, AWS, etc.)
- Resources are unique based on the integration (e.g. GitHub lists repositories, Slack list conversations, AWS lists EC2 instances, etc.)
- Each integration is unique and has its own set of complexities, endpoints, steps, etc.
- Each integration may produce different errors at any time (e.g. Authentication invalid, resource does not exist, etc.)
I won't be focusing on the challenges of maintaining such integrations but only observing them.
🌳 The nature of logging: good logging matters
(Google SEO, please, don't relate this post to forests 🙏).
First, let's analyze the log characteristics.
Logs are:
- Descriptive;
- Contextual;
- Reactive;
They're descriptive in the sense that they give you a piece of information, they're contextual because they give you an overview of the state of things at the moment, and finally, they're reactive because they allow you to take action only after something happened (even though your logs are sent/consumed real-time, there's not really something you can do to change what just happened).
If you don't respect the nature of a log, you're going to produce only noise, which decreases your performance.
Here, take some examples based on the system we defined together:
If you give it a description like "operation connect failed", but don't give context, it's hard to understand which integration failed, who was affected, what step of the connection it failed, thus you can't react! You'll end up digging into more logs and having no clue but just guesses on what could be the issue.
Oh, also don't underestimate a developer's capacity to ruin the descriptive characteristic. It can be easily done by giving shallow messages with no context at all like: "An error happened", or "An unexpected exception was raised". By reading it I can't even consider the impact of an error, because I don't know WHAT failed. So, yes, it's possible to ruin the core nature of a log.
Logs are private intel from your software to keep you aware and react to situations. Any log that can't give you this ability is pure noise.
⏲️ When to log?
To keep logs "reactive" you need to log "events". Make them as clear and easy to read as this blog post, maybe you didn't read every single line I wrote above, but you can still follow up, skip sections you don't want, and focus/read what caught your attention. Logs should be the same.
As a rule of thumb consider logging:

- At the start of relevant operations or flows (e.g. Connection to third-party, etc);
- At any relevant progress (e.g. Authentication successful, got a valid response code, etc);
- At the conclusion of an operation (e.g. EITHER succeeded or failed);
Logs should tell you a story, every story has a beginning, middle, and end.
Be strict with "relevant", it's easier to add logs than to remove them, anything below relevant is noise.
🪵 What to log?
To keep logs "descriptive" and "contextual", you need to provide the correct set of information, and that's impossible to tell you which are they without knowing your case. Let's use our example instead.
Consider the AWS integration from our example, It would be great to have:
Successful logs example
| Message | Instant knowledge | Context |
|---|---|---|
Connecting to AWS
|
AWS operation started | Log attributes should allow me to find out who triggered it |
Retrieved instances from all regions
|
One relevant progress has been made | - |
Connection to AWS has been successful
|
AWS operation finished | Log attributes should allow me to find who got positively affected |
Error logs example
Consider that retrieving instances from region af-south-1 failed due to some random issue over that region.
| Message | Instant knowledge | Context |
|---|---|---|
Connecting to AWS
|
AWS operation started | Log attributes should allow me to find out who triggered it |
Failed to retrieve instances from regions af-south-1 when connecting to AWS for user X
|
AWS operation didn't finish, region af-south-1 failed,
user X got
affected |
I should be able to see the error's stack trace to dive into the "why" it failed |
For both cases, I can track when something happened (logs have timestamps), what happened, and who got affected.
I decided to not refer the user when the operation starts and succeeds because it's irrelevant (so it's noise), see:
- If I know something started, and don't even know the result - what can I do?
- If everything seems fine, why should I bother?
Adding such data make logs noisy because they're impossible to react: I got nothing to do! I still should be able to gather details by reading attributes (who, when, why, etc). If you're willing to measure something you should be using metrics, not logs.
On the other side, the error log seems way more verbose, and it should be! Reading these logs makes me confident enough to act RIGHT AWAY:
- Ask a dev to check AWS status on the region
af-south-1, and maybe run some sanity checks; - Call user X and proactively notify him you're aware of the issue that is affecting that region;
The key point here is: You can react RIGHT AWAY, no deeper investigation is needed to. You know everything you have to, and you can take immediate action to reduce impact. Developers might need to dig deeper into stack traces to gather more context (in case of a bug), but the big picture is already clear.
Any other error message missing these minimum info becomes noise because it raises concern, but takes away your condition to react. You need to investigate first to acknowledge how bad is the issue.
If still unsure of how to build such messages, I'll share a very simple hack with you.
Always ask yourself:
If I read this log, what I'd wish to understand after reading it?
🐍 Providing context with Python
Log attributes can be added in Python by using the extra field, like:
# Do that
logger.info("Connecting to AWS", extra={"user": "X"})
...
logger.info("Connection to AWS has been successful", extra={"user": "X"})
Context doesn't replace the need for meaningful messages! So, I'd advise against:
# Don't do that
logger.info("Connecting to third-party", extra={"user": "X", "third-party": "AWS"})
Messages should be clear and leave no room for questions about what's going on. Context should enrich the experience by providing info about deeper details and allow you to find out why something happened.
🚦 There's more than just logger.info and logger.error
It's really hard to catch up with what's going on when thousands of customers are triggering "Connecting to Slack" logs. As you produce logs and several customers use your application, you should be able to filter information by relevance.
Logs may contain many levels (i.e. relevance level). In Python, you can find DEBUG, INFO, WARNING, ERROR, CRITICAL. I recommend you use all of them.
To make things simple, here's a rule of thumb for you (be flexible!):
| Level | When to use |
|---|---|
DEBUG
|
For some really repetitive information. It might be useful to understand the whole context of what's going on, most of the time it's not so useful. |
INFO
|
When something relevant happened, something worthy of being aware of most of the time. |
WARNING
|
Something weird happened (but didn't interrupt the flow/operation). If any other issue happens later on it might give you a hint. |
ERROR
|
An error happened, it should be resolved as soon as possible. |
CRITICAL
|
A very serious error happened, it needs immediate intervention.
Prefer ERROR if
unsure. |
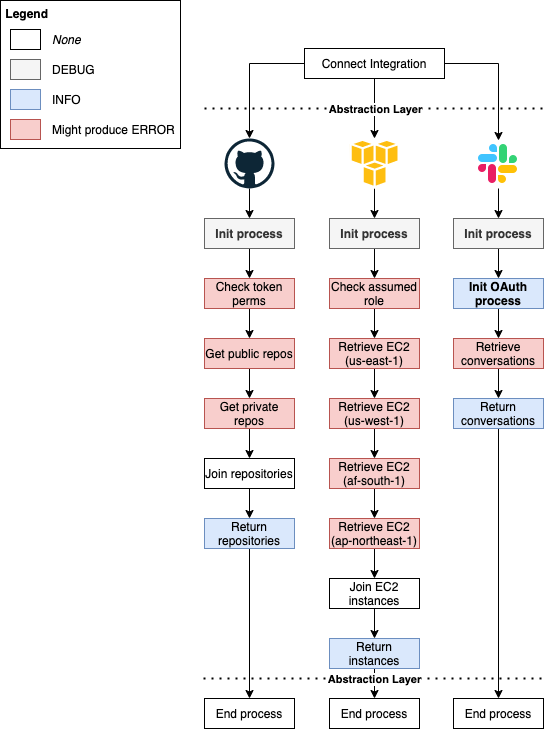
Given the system/flows we defined together, I would use the log levels as defined:
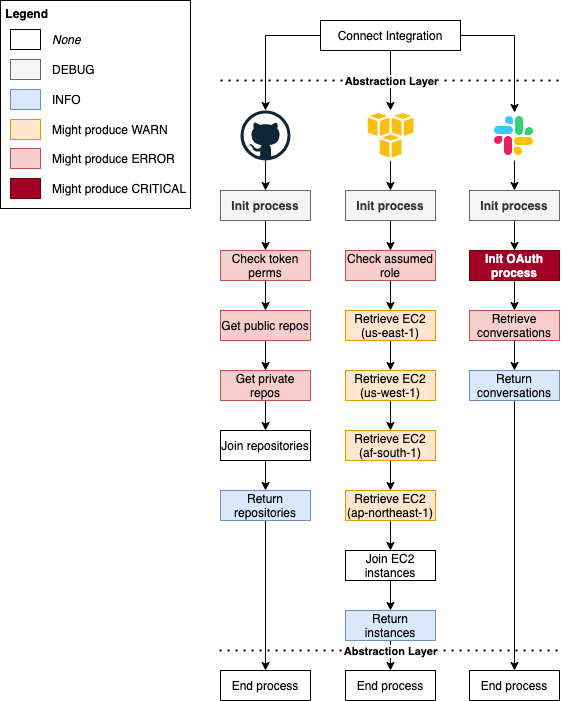
🟠🔴 What about logger.critical and logger.warning?
Just for the sake of example, I want to cover cases where I would consider using WARNING and CRITICAL as well.
WARNINGis no good reason for stopping a flow, but it's a heads up if any other issue happens later.CRITICALshould be the most alarming log you're ever going to receive, it should be a good excuse to wake you up at 3 am to resolve.
For such cases, we're going to consider:
- For AWS: if any AWS region is unavailable, we can assume the user doesn't have any resources over there, so we can move on.
- For Slack: if OAuth fails due to an invalid client id, it means all other users will face the same issue, the integration is unusable until we manually generate a new id. It seems pretty critical to me.
⚪ Unpopular opinion: Use debug level on production
Yes, I do believe debug logs should be used in production.
The other way around would be to: Only enable debug after something weird needs deeper investigation.
Sorry, it's unbearable to me.
In the real world, customers need quick response, teams need to deliver their work, and keep systems up and running all the time. I don't have the time or the bandwidth to make a whole new deployment or to enable a flag and expect the issue to repeat. I must react to unexpected issues in seconds, not minutes.
🏗️ Set up your logger correctly
Finally, I notice people struggling when setting up the logger (or don't setting it up at all). Indeed, Python docs are not friendly, but that's no good excuse for you to not do it properly.
There are some ways for you to configure it, you can use logging.config.dictConfig, logging.config.fileConfig, or even manually by calling commands like: setLevel, addHandler, addFilter.
From my experience:
- Using manual commands are hard to maintain and understand;
fileConfigis inflexible, you can't have dynamic values (without tricks);dictConfigis simple enough to start and to set;
So we're sticking to dictConfig as an example. We could also trigger a basicConfig, but most of the time if you have set up your logger correctly I don't think you need that!
I'll start sharing small bits of advice and definitions you should know, and then we're going to build the final config together with real examples from projects that I work on.
Here's a cheat sheet of what's coming next:
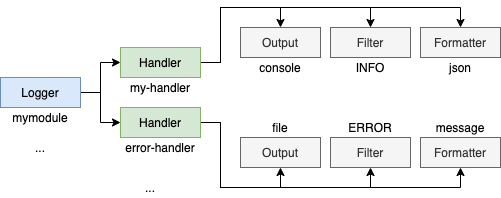
💠 What are loggers?
Loggers are objects you instantiate through logging.getLogger that allow you to produce messages. Each individual logger can be bound to a configuration with its own set of formatters, filters, handlers, etc.
The most interesting part is that loggers are hierarchical and all of them inherit from the root logger. Further inheritance is defined by "." (dots), like: mymodule.this.that is child of mymodule.this.
See:
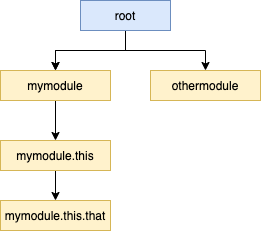
Because of that, Python docs recommend using logger.getLogger(__name__), because __name__ will return the current package namespace.
So, in short, stick to:
import logging
logger = logging.getLogger(__name__)
def myfunc():
...
logger.info("Something relevant happened")
...
Heads up: You can refer to the root logger by either using the name root, an empty string: "", or none at all. Yes, it's confusing. Use root for verbosity and clarity.
🥨 Format your logs
Formatters are invoked to output the final message and are responsible for converting it to the final string.
Back when I worked at Zak (former Mimic) and even today at Lumos we format logs as JSON. That's a good standard for systems running in production that may contain many attributes. It's easier to visualize JSON than a regular long string, and you don't have to create your own formatter for that (check out python-json-logger).
Production systems should log in JSON
— Gui Latrova (@guilatrova) August 26, 2022
I recently joined a startup and had to implement the logging from the scratch.
💁🏻♂️ See REAL screenshots/logs of how JSON logging helps in monitoring production systems.
🧵👇 5 benefits of using it w/ 🐍 Python + AWS CloudWatch examples
For local development, I do recommend sticking to the default formatting due to simplicity.
Such a decision depends on the kind of project. For Tryceratops 🦖✨ I decided to go with the regular formatter because it's simpler and runs locally - no need for JSON there.
🔭 Filter your logs
Filters can be used to either filter (duh) logs or even add additional context to the log record. Consider filters as hooks being invoked before the final log is processed.
They can be defined like:
class ContextFilter(logging.Filter):
USERS = ['jim', 'fred', 'sheila']
IPS = ['123.231.231.123', '127.0.0.1', '192.168.0.1']
def filter(self, record): # Add random values to the log record
record.ip = choice(ContextFilter.IPS)
record.user = choice(ContextFilter.USERS)
return True
Or they can be added straight to the logger OR handler for simpler filtering based on level (examples on this soon).
🪢 Handle your logs and how everything is connected
Handlers are combinations of formatters, outputs (i.e. streams), and filters.
It allows me to create combinations like:
- Output all logs from
info(filter) onwards, to console (output) asJSON(formatter). - Output all logs from
error(filter) onwards, to a file (output) containing just message and stack trace (formatter).
Finally, loggers point out to handlers.
🍖 logging.dictConfig example
Now that you understand what these objects do, let's start defining ours! As always, I'll strive to show you real-life examples! I'll be using Tryceratops 🦖✨ config. Feel free to open the link and see the final config yourself.
🦴 Logging config: boilerplate
This is the skeleton to get started, we create a LOGGING_CONFIG constant like:
import logging.config
LOGGING_CONFIG = {
"version": 1,
"disable_existing_loggers": False,
"formatters": { },
"handlers": { },
"loggers": { },
"root": { },
}
logging.config.dictConfig(LOGGING_CONFIG)
Some takeaways:
versionis always 1. It's a placeholder for possible future Python releases. So far Python does not have any other version yet!- I recommend keeping
disable_existing_loggersFalseto avoid your system from swallowing other unexpected issues that might happen. If you want to modify some other loggers I recommend (although boring) overwriting them explicitly! - The outer
rootkey as you might wonder, define the highest logger to be inherited
You can define the same root logger in 3 different ways, which is just confusing:
LOGGING_CONFIG = {
"version": 1,
...
"loggers": {
"root": ... # Defines root logger
"": ... # Defines root logger
},
"root": { }, # Define root logger
}
Pick just one! I like keeping it outside because it makes it obvious and (somewhat) verbose, what I want because the root logger affects every other logger defined.
🥨 Logging config: formatters
I'll enrich the Tryceratops 🦖✨ example with a JSON example from Lumos.
Note that any %([name])[type] like %(message)s and %(created)f tells the formatter what to display, and how to display it.
LOGGING_CONFIG = {
...,
"formatters": {
"default": { # The formatter name, it can be anything that I wish
"format": "%(asctime)s:%(name)s:%(process)d:%(lineno)d " "%(levelname)s %(message)s", # What to add in the message
"datefmt": "%Y-%m-%d %H:%M:%S", # How to display dates
},
"simple": { # The formatter name
"format": "%(message)s", # As simple as possible!
},
"json": { # The formatter name
"()": "pythonjsonlogger.jsonlogger.JsonFormatter", # The class to instantiate!
# Json is more complex, but easier to read, display all attributes!
"format": """
asctime: %(asctime)s
created: %(created)f
filename: %(filename)s
funcName: %(funcName)s
levelname: %(levelname)s
levelno: %(levelno)s
lineno: %(lineno)d
message: %(message)s
module: %(module)s
msec: %(msecs)d
name: %(name)s
pathname: %(pathname)s
process: %(process)d
processName: %(processName)s
relativeCreated: %(relativeCreated)d
thread: %(thread)d
threadName: %(threadName)s
exc_info: %(exc_info)s
""",
"datefmt": "%Y-%m-%d %H:%M:%S", # How to display dates
},
},
...
}
Note that the names we're setting there (default, simple, and JSON) are arbitrary but relevant. We're going to refer them soon.
🪢 Logging config: handlers
ERROR_LOG_FILENAME = ".tryceratops-errors.log"
LOGGING_CONFIG = {
...,
"formatters": {
"default": { ... },
"simple": { ... },
"json": { ... },
},
"handlers": {
"logfile": { # The handler name
"formatter": "default", # Refer to the formatter defined above
"level": "ERROR", # FILTER: Only ERROR and CRITICAL logs
"class": "logging.handlers.RotatingFileHandler", # OUTPUT: Which class to use
"filename": ERROR_LOG_FILENAME, # Param for class above. Defines filename to use, load it from constant
"backupCount": 2, # Param for class above. Defines how many log files to keep as it grows
},
"verbose_output": { # The handler name
"formatter": "simple", # Refer to the formatter defined above
"level": "DEBUG", # FILTER: All logs
"class": "logging.StreamHandler", # OUTPUT: Which class to use
"stream": "ext://sys.stdout", # Param for class above. It means stream to console
},
"json": { # The handler name
"formatter": "json", # Refer to the formatter defined above
"class": "logging.StreamHandler", # OUTPUT: Same as above, stream to console
"stream": "ext://sys.stdout",
},
},
...
}
Note that if you use logging.fileConfig it would be impossible to have a nice constant like ERROR_LOG_FILENAME, you can even read this from environment variables if you wish.
Also, notice that the classes/params I use for handlers weren't created by me. They're from the logging library, and there's more than just those!
💠 Logging config: loggers and root
LOGGING_CONFIG = {
...,
"formatters": {
"default": { ... },
"simple": { ... },
"json": { ... },
},
"handlers": {
"logfile": { ... },
"verbose_output": { ... },
"json": { ... },
},
"loggers": {
"tryceratops": { # The name of the logger, this SHOULD match your module!
"level": "INFO", # FILTER: only INFO logs onwards from "tryceratops" logger
"handlers": [
"verbose_output", # Refer the handler defined above
],
},
},
"root": { # All loggers (including tryceratops)
"level": "INFO", # FILTER: only INFO logs onwards
"handlers": [
"logfile", # Refer the handler defined above
"json" # Refer the handler defined above
]
}
Let's understand what's going on:
- Inside
root, we define every single log exceptDEBUGones to be handled by bothlogfileandJSONhandlers logfilehandler filters onlyERRORandCRITICALlogs, and output them to a file usingdefaultformatterJSONaccepts all incoming logs (no filter), and output them to console usingJSONformattertryceratopsoverrides some configs inherited byroot, likelevel(even though it's the same), andhandlersto use justverbose_outputverbose_outputaccepts all incoming logs (filter toDEBUG), and output them to console usingsimpleformatter
The tryceratops logger name is very important and should match loggers I'll be creating later on. For our project example, anytime I do: logger.getLogger(__name__) inside of the module I get names like: tryceratops.__main__, tryceratops.runners, or tryceratops.files.discovery, and all of them match the rule we created.
I defined a new set of handlers for tryceratops, but any other logger (including from third-party libraries) will use the ones from the root.
Also, notice that I can overwrite default rules. Over settings or dynamically later on. For example, whenever tryceratops receives a verbose flag from CLI, it updates the logging config to include debug.
Did you enjoy what you just read? Consider subscribing in the form below so you don't miss any other posts and following me to receive more bite-sized tips.
Also, logging is important, but having well-structured exceptions and try/except blocks are as much important as it, so you might want to read how to handle your exceptions in Python like a PRO and how to structure exceptions in Python like a PRO.
