How to run pytest in parallel on GitHub actions
In my current company, we write lots of integration tests. Integration tests are great because they encompass the whole functionality of a use case end to end which frequently includes the database.
The downside is that it tends to be slow. As for each test you need to set up the data before, execute, and then clear the database for the next tests.
As you write many tests it's expected the whole suite case will take ~5min to complete or even more. Today it takes around ~12min.
This is not good for Pull Requests as opening any PR would take 12 minutes to allow any developer to merge his work:
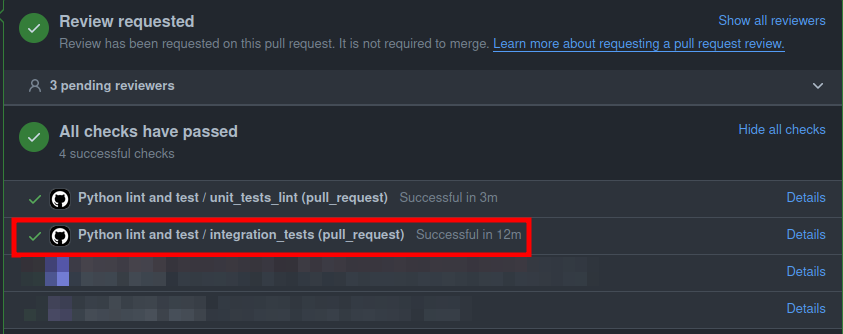
This is too slow to merge a PR. The quickest way to improve our time would be to parallelize the integration tests.
As result we cut down the time back to ~5min which is +50% performance improvement with a small effort:
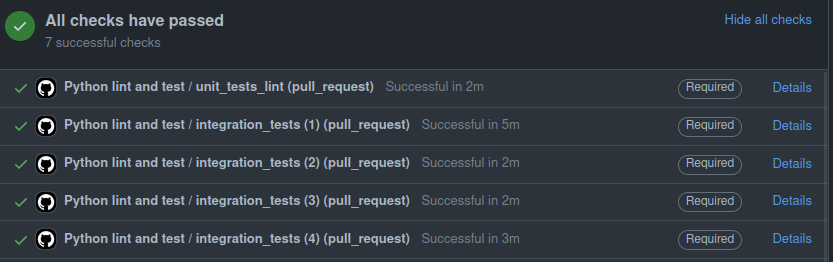
In this article, I'm going to explain what was done and how you can reproduce it in your environment.
I know CircleCI has a feature and guide dedicated to splitting tests that is even easier to use and set up, but this is not common for other CIs. For GitHub Actions we had to implement something similar ourselves.
🐢 How it was before
We had two parallel jobs already:
- Unit testing and linting (~2min)
- Integration testing (~13min)
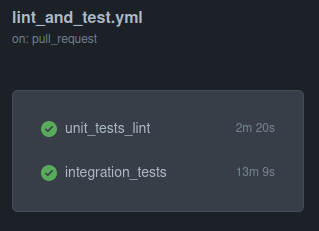
For integration testing we need to use MongoDB and Redis to test our features end to end so we get one container up for each.
We have some Machine Learning and AWS specific tests, so we decided to exclude them from our Pull Request checks and just test them locally.
name: Python lint and test
on:
pull_request:
permissions:
contents: read
jobs:
unit_tests_lint: # 👈 We're not intested as these are fast enough
runs-on: ubuntu-latest
steps: ...
integration_tests: # 👈🎯 Focus here
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: ./.github/workflows/setup_python # 👈 Installs/Caches poetry
- run: mv ./.github/.env .env # 👈 Default vars for our tests
# 👇 Allows our docker compose to be used within GitHub container
- uses: KengoTODA/actions-setup-docker-compose@main
with:
version: "1.29.2"
# 👇 Now we can just get the services we use up
- run: docker-compose up -d mongo redis
# 👇 Executes our integration test suite
- name: Integration Tests without ML
run: poetry run pytest src/tests/integration -m 'not (ml or aws_deps)'
🔀 Pytest split tests
We want somehow to split the tests into groups so we can test them in parallel.

Before explicitly touching the GitHub workflow yaml, we need to teach pytest how to split tests.
Luckily pytest supports hooks we can leverage to achieve our goal.
For this, we need pytest_collection_modifyitems which we create inside src/tests/integration/conftest.py.
We need to create the conftest file inside the proper directory otherwise, it might affect all tests (including unit ones which we don't want to parallelize).
Picture something as:
src
└── tests
├── unit
│ ├── test_xxx.py
│ └── test_yyy.py
│
└── integration
├── conftest.py # 👈
├── test_xxx.py
└── test_yyy.py
Let's start with this stub, and increment slowly:
import pytest
def pytest_collection_modifyitems(
session: pytest.Session,
config: pytest.Config,
items: list[pytest.Item] # 👈 Contains an ordered list of tests pytest found
) -> None:
selected = [...] # Decide how to split/pick
deselected = [...] # Decide how to deselect remaining tests
config.hook.pytest_deselected(items=deselected) # 👈 Marks as deselected
items[:] = selected # 👈 Overwrites current selection
We need something robust that achieves three minor objectives:
- (Local DevExp) Identify when running locally so we don't split
- (Purpose) Smartly select the proper range for each worker
- (Maintenance) Be easily extensible to X workers
My approach here was to take environment variables as optional arguments:
| Environment variable | Purpose | Example value |
|---|---|---|
| GITHUB_WORKER_ID | Holds the current worker id | 1 |
| GITHUB_TOTAL_WORKERS | Counts how many workers we have in total | 400 |
Now we can start filling in these values:
import math
import os
import pytest
def pytest_collection_modifyitems(
session: pytest.Session,
config: pytest.Config,
items: list[pytest.Item]
) -> None:
# 👇 Make these vars optional so locally we don't have to set anything
current_worker = int(os.getenv("GITHUB_WORKER_ID", 0)) - 1
total_workers = int(os.getenv("GITHUB_TOTAL_WORKERS", 0))
# 👇 If there's no workers we can affirm we won't split
if total_workers:
# 👇 Decide how many tests per worker
num_tests = len(items)
matrix_size = math.ceil(num_tests / total_workers)
# 👇 Select the test range with start and end
start = current_worker * matrix_size
end = (current_worker + 1) * matrix_size
# 👇 Set how many tests are going to be deselected
deselected_items = items[:start] + items[end:]
config.hook.pytest_deselected(items=deselected_items)
# 👇 Set which tests are going to be handled
items[:] = items[start:end]
print(f" Executing {start} - {end} tests")
Now you can run your integration tests locally and... Nothing changed which is our goal.
🐇 Split pytest tests across GitHub workers
Whenever we want to spin multiple workers on GitHub we use matrix and pass any values we want. It designs a custom worker for each matrix value.
This is commonly used to run tests in different OS or python versions. Take this example from Gracy.
We run the same suite for Linux only (1) across 4 Python versions. So 1 * 4 = 4 parallel workers running tests.
For our case, we just want to assign worker ids (bare ints) which is fine to do as:
integration_tests:
runs-on: ubuntu-latest
+ strategy:
+ matrix:
+ worker_id: [1, 2, 3, 4]
steps:
- uses: actions/checkout@v3
- uses: ./.github/workflows/setup_python
- run: mv ./.github/.env .env
- uses: KengoTODA/actions-setup-docker-compose@main
with:
version: "1.29.2"
- run: docker-compose up -d mongo redis
+ # 👇 We need to set up the env vars from values taken from the matrix
+ - name: Set up worker env vars
+ run: |
+ echo "GITHUB_WORKER_ID=${{matrix.worker_id}}" >> $GITHUB_ENV
+ echo "GITHUB_TOTAL_WORKERS=4" >> $GITHUB_ENV
+ # 👇 Rename to something clearer
- - name: Integration Tests without ML
+ - name: Integration Tests without ML - Worker. ${{matrix.worker_id}}
run: poetry run pytest src/tests/integration -m 'not (ml or aws_deps)'
Note for this case I explicitly defined GITHUB_TOTAL_WORKERS to 4, so our snippet will count all the tests we have and split them evenly for each worker.
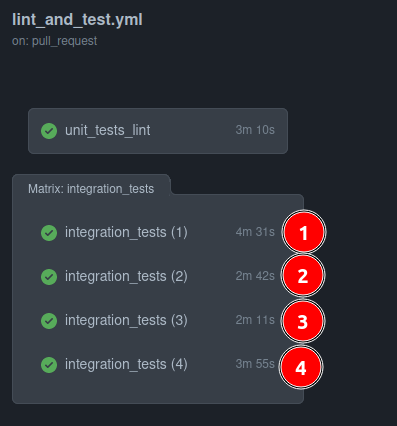
Using this example, each dev that wants to merge a PR will have to wait for ~4m in contrast to ~13min before.
There's still space for further improvement though:
| Worker | Time Spent |
|---|---|
| 3 | 2m 11s |
| 2 | 2m 42s |
| 4 | 3m 55s |
| 1 | 4m 31s |
Worker 3 finished early while Worker 1 kept running for another ~2min.
This means that if we group and better split slow tests for each worker to each worker we can probably get all done in around ~3m 30s.
This feels like an idea for another blog post though.
If you learned something new today consider giving me a follow on X.
